The Challenge
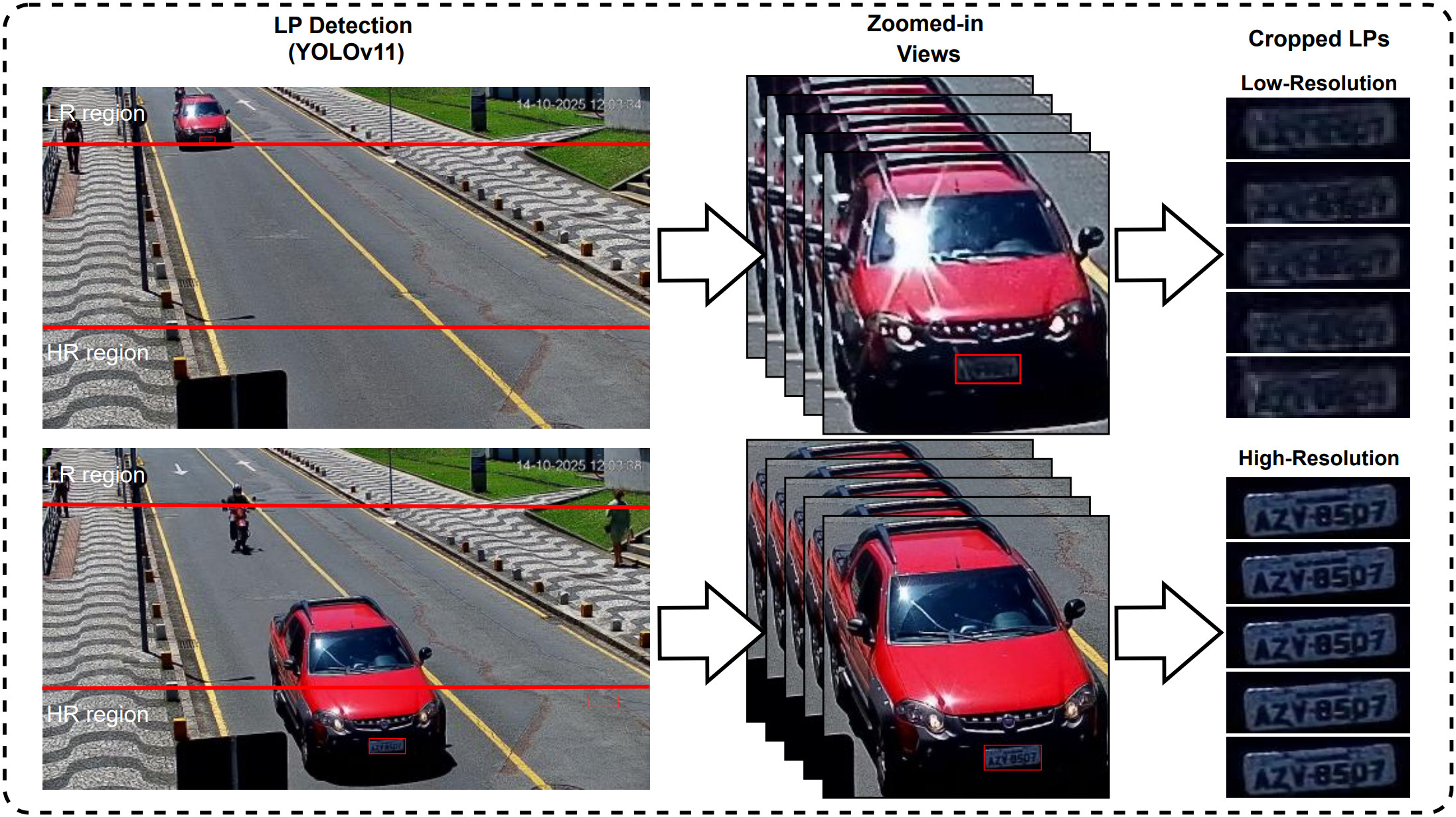
In surveillance contexts, license plate images are frequently captured at low resolutions or subjected to heavy compression due to storage and bandwidth limitations. Consequently, characters often become distorted, blend into the background, or overlap with neighboring symbols, making automated recognition particularly challenging.
Recognizing these low-resolution license plates remains a highly challenging and underexplored problem with strong forensic and societal relevance. The difficulty is evident in the fact that even state-of-the-art methods currently struggle to surpass 50-60% recognition accuracy. Improving recognition performance under such adverse conditions, therefore, offers a significant opportunity to substantially narrow investigative searches and expedite law enforcement decisions. This competition aims to encourage the development of advanced approaches, such as super-resolution, temporal modeling, and robust Optical Character Recognition (OCR) techniques, capable of operating effectively despite low-quality input conditions.
Dataset

Training Data (LR + HR images)
-
Scenario A (10,000 tracks): obtained from a recently published dataset (Nascimento et al., 2025). These tracks were collected under relatively controlled environmental conditions (e.g., no rain and only during daylight hours).
- Each track includes annotations for the license plate text, layout, and corner positions.
-
Scenario B (10,000 tracks): newly collected specifically for this competition, using the same camera as Scenario A but oriented in a different direction. These tracks were captured under a wider range of environmental conditions (Figure 3).
- Each track includes annotations for the license plate text and layout. Corner annotations are not provided.
-
Access to the training data: see Get Started. The dataset will be made available exclusively for non-commercial use and only to institutional email addresses from educational or research organizations.
Test Data (LR Images Only)
-
Images per Track: 5 Low-Resolution (LR) images.
Note: High-Resolution (HR) images are provided exclusively for training, so participants may explore image enhancement techniques.
-
Public Test Set (1,000 Tracks): tracks sourced from Scenario B, used for public leaderboard ranking.
Note: This set is a subset of the Blind Test Set.
-
Blind Test Set (3,000+ Tracks): tracks sourced from Scenario B, used for final competition ranking.
-
Submission Format: Participants in the competition are required to submit a
.zipfile containing a single.txtfile where each line contains the prediction for one track using the following format (detailed instructions are available on Codabench):track_00001,ABC1234;0.9876 track_00002,DEF5678;0.6789 track_00003,GHI9012;0.4521 ...Each line consists of:
track_id,plate_text;confidence.- Participants may use any method to aggregate predictions across the five LR images (e.g., majority voting, confidence-based selection, temporal modeling).

Competition Schedule
Dec 15, 2025
Registration Opens
Website goes live
Dec 18, 2025
Training Set Releases
Competition starts
Jan 19, 2026
Public Test Set Releases
~30% of the blind test data (used for public leaderboard)
Feb 8, 2026
Registration Ends
Final deadline for new registrations and updating team composition
Feb 23, 2026
Blind Test Set Releases
Official test data (used for final ranking)
Mar 1, 2026
Submission Deadline
Competition ends
ICPR 2026 Presentation:
The competition summary paper will be presented at ICPR 2026 in August 2026 and will subsequently be published in the conference proceedings.
Get Started
Step by step
- Read the rules: please review the Rules section below to ensure your participation and submissions comply with all requirements;
- Access the training data: download and sign the license agreement, then submit the signed document via the ICPR26-LRLPR Dataset Request Form. A Gmail account is required to submit the agreement through the form; however, you must provide an institutional email address in the designated field. The dataset will be made available exclusively for non-commercial use and only to institutional email addresses associated with educational or research organizations (e.g., .edu, .ac, or similar). After submitting the request and completing your registration for the competition on Codabench, you will receive a download link for the training dataset (please check your spam/junk folder after a few days);
- Develop your method: predictions must be based exclusively on the five low-resolution (LR) images provided per track. High-resolution images are available only in the training set, so participants may explore image enhancement techniques;
-
Submit your predictions:
run your model locally on the public or blind test set and generate a
.txtfile (e.g.,predictions.txt) that strictly follows the required format. Compress this file into a.ziparchive (e.g.,submission.zip) and upload it through the My Submissions tab on Codabench. Before submitting, please carefully review the Submission Guidelines tab available on Codabench.
Rules
- Research use and results authorization: the provided dataset is intended solely for research purposes. By participating in the competition and submitting results, you grant the organizers permission to analyze the submissions and to use the results in aggregate form for reports, publications, and presentations related to the challenge;
-
Team composition:
each participating team may consist of up to five participants;
- A participant may be a member of only one team throughout the competition. Participants from the same research group are not allowed to register multiple teams. The organizers reserve the right to limit the number of accepted submissions per affiliation and to determine which submissions (from the same affiliation) will be considered for ranking and awards;
- The primary affiliation of the team must match the information provided in the registration form. For top-ranked teams, the organizers reserve the right to remove or anonymize industry names from the team name, due to dataset restrictions related to non-commercial use.
-
Use of external data:
external training data is permitted, but its source and usage must be clearly documented by top-ranked teams. Teams that rely on external data will be required to report results obtained using only the provided training dataset;
- For teams seeking additional training data beyond the competition split, the well-known UFPR-ALPR and RodoSol-ALPR datasets are publicly available for research purposes (access to these datasets is granted upon request and subject to their respective usage terms). We remark that despite their broad adoption in the ALPR literature, both datasets predominantly contain high-resolution license plates and therefore do not reflect the low-resolution conditions addressed by this competition.
- No manual labeling: manual inspection or annotation of the test sets is strictly prohibited. All predictions must be generated exclusively by automated methods, with no human intervention or post-processing. If deemed necessary by the organizers, top-ranked teams may be required to submit their code to the organizers or make it publicly available. This may include a complete and fully reproducible training and inference pipeline, used solely to verify that the reported results were obtained algorithmically and without any use of test data during training;
- Disqualification: any form of cheating or violation of the competition rules, including registering with false or misleading information, participating in more than one team, unfairly exploiting in any way the Codabench platform, or submitting results that do not reflect the original work of the registered team (e.g., plagiarism or reuse of others’ results without proper attribution), will result in immediate disqualification.
Evaluation Criteria
📊 Primary Metric: Recognition Rate (Exact Match)
The official ranking is based on the Recognition Rate computed over the Blind Test Set.
How Recognition Rate is Computed
Criteria for a Correct Prediction
- A track is considered correct only when all predicted characters match the ground truth exactly;
- If any character differs, the track is not counted as correct.
⚖️ Tie-Breaker: Confidence Gap
If two or more teams achieve the same Recognition Rate, the tie will be broken using a metric called Confidence Gap.
How Confidence Gap is Computed
Ranking Rule
- The team with the largest Confidence Gap ranks higher.
- A larger gap reflects better confidence separation between correct and incorrect predictions.
Competition Platform
The competition is hosted on Codabench.
For details on the required submission file, please see Submission Format.
For the public test set, teams are subject to the following submission limits:
- 5 submission per day;
- 25 total submissions over the competition period.
Reminder: please review the Rules before participating.
🏆 Recognition & Publication
- All teams that submit predictions for the blind test set will receive a certificate of participation from the competition organizers;
- The top 3 participating teams will receive certificates of achievement from the ICPR 2026 committee;
- The top 5 teams will be invited to contribute to the competition summary paper to be included in the ICPR 2026 proceedings.
- Additional teams may be invited to contribute, contingent upon the final ranking and the overall number of participating teams.
FAQ (Summary)
Q: How large can a team be?
A: Each team may have up to five participants.
Q: We would like to participate. What do we need to do?
A: Complete the ICPR26-LRLPR Dataset Request Form by providing your contact details, institutional affiliation, team members, and your Codabench username. In addition to submitting the form, you must also complete your registration on the Codabench competition page. A Gmail account is required to submit the license agreement through the form; however, you must provide an institutional email address in the designated field. Follow the instructions in the form and submit it to register.
Q: What are the requirements to download the dataset?
A: Dataset access is granted after completing and submitting the license agreement through the ICPR26-LRLPR Dataset Request Form and registering for the competition on the Codabench platform. Registration must use an institutional email address from an educational or research organization, such as domains ending in .edu, .ac or similar.
Q: How will the submissions be evaluated?
A: Submissions will be evaluated on the Blind Test Set using the Recognition Rate, which measures the proportion of tracks whose predicted license plate text exactly matches the ground truth. Additional details, including the tie-breaking procedure based on Confidence Gap, are described in the Evaluation Criteria section.
Q: What are the prizes?
A: The top three teams will receive certificates of achievement from the ICPR 2026 committee. The top five teams will be invited to contribute to the competition summary paper to be published in the ICPR 2026 proceedings (subject to peer review). Depending on the final ranking, additional teams may also be invited to contribute.
Q: Can we use external datasets to train our models?
A: Yes. The use of additional training data is allowed, but its source and usage must be clearly documented. Top-ranked teams that use external data will also be required to submit results obtained using only the provided training dataset.
Q: Can the test sets be used in any way during training?
A: No. Manual annotation or any use of test data for training is strictly prohibited. To verify that results were obtained through a fully algorithmic process and without access to test data, top-ranked teams may be asked, if deemed necessary by the organizers, to submit their code to the organizers or make it publicly available.
Q: Will we need to submit our code?
A: Not necessarily. If deemed necessary by the organizers, top-ranked teams may be asked to either submit their code to the organizers or make it publicly available. This may include a complete and reproducible training pipeline, used solely to confirm that the results were obtained algorithmically and without any use of test data for training.
Q: How can we contact the organizers?
A: For any questions about the competition, please contact us at icpr26lrlpr@gmail.com.
Organizing Committee

Rayson Laroca
Professor, PUCPR & UFPR, Brazil
Professor at the Pontifical Catholic University of Paraná (PUCPR), Brazil. Actively engaged in automatic license plate recognition research since 2018. He has developed widely adopted benchmarks in the field, including UFPR-ALPR and RodoSol-ALPR, which have become reference datasets for the research community. His conference and journal publications have helped shape the current state of the art in the field.

Valfride Nascimento
PhD Candidate, UFPR, Brazil
PhD candidate at the Federal University of Paraná (UFPR), Brazil, where his research focuses on license plate super resolution. His proposed methods have demonstrated superior performance compared to general-purpose and domain-specific approaches, bridging the gap to real-world forensic scenarios.

David Menotti
Full Professor, UFPR, Brazil
Full Professor at the Federal University of Paraná (UFPR), Brazil. Actively engaged in automatic license plate recognition research since 2010. Extensive experience in computer vision, especially in surveillance applications. Achieved top-ranked results in several international challenges and consistently listed by Elsevier among the world's top two percent most influential researchers.


Selected References
• V. Nascimento, G. E. Lima, R. O. Ribeiro, W. R. Schwartz, R. Laroca, D. Menotti, "Toward Advancing License Plate Super-Resolution in Real-World Scenarios: A Dataset and Benchmark," Journal of the Brazilian Computer Society, vol. 31, no. 1, pp. 435-449, 2025;
• H. Gong, Z. Zhang, Y. Feng, A. Nguyen, H. Liu, "LP-Diff: Towards Improved Restoration of Real-World Degraded License Plate," IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 17831-17840, 2025;
• R. Laroca, V. Estevam, G. J. P. Moreira, R. Minetto, D. Menotti, "Advancing Multinational License Plate Recognition Through Synthetic and Real Data Fusion: A Comprehensive Evaluation," IET Intelligent Transport Systems, vol. 19, no. 1, p. e70086, 2025;
• K. Na, J. Oh, Y. Cho, B. Kim, S. Cho, J. Choi, I. Kim, "MF-LPR2: Multi-frame License Plate Image Restoration and Recognition Using Optical Flow," Computer Vision and Image Understanding, vol. 256, p. 104361, 2025;
• V. Nascimento, R. Laroca, R. O. Ribeiro, W. R. Schwartz, D. Menotti, "Enhancing License Plate Super-Resolution: A Layout-Aware and Character-Driven Approach," in Conference on Graphics, Patterns and Images (SIBGRAPI), pp. 1-6, Sept. 2024;
• R. Laroca, L. A. Zanlorensi, V. Estevam, R. Minetto, D. Menotti, "Leveraging Model Fusion for Improved License Plate Recognition," in Iberoamerican Congress on Pattern Recognition (CIARP), pp. 60-75, Nov. 2023;
• V. Nascimento, R. Laroca, J. A. Lambert, W. R. Schwartz, D. Menotti, "Super-Resolution of License Plate Images Using Attention Modules and Sub-Pixel Convolution Layers," Computers & Graphics, vol. 113, pp. 69-76, 2023.